


How Do LLMs Work?
From distances to data to the inner workings of AI — demystified.
📋 What's In This Lesson
Three connected topics that build your mental model of modern AI: how machines measure similarity, where your data actually lives, and what happens when an LLM encounters questions it can't answer.
🎯 Why This Matters (WIIFM)
Whether you're evaluating AI tools or leading a team that uses them, understanding how LLMs find, process, and fail with data is now a core professional skill. This lesson gives you that foundation.
📐 Topic 1: Manhattan Distance
Imagine you're a taxi driver in New York City. You can't drive diagonally through buildings — you must follow the grid of streets.
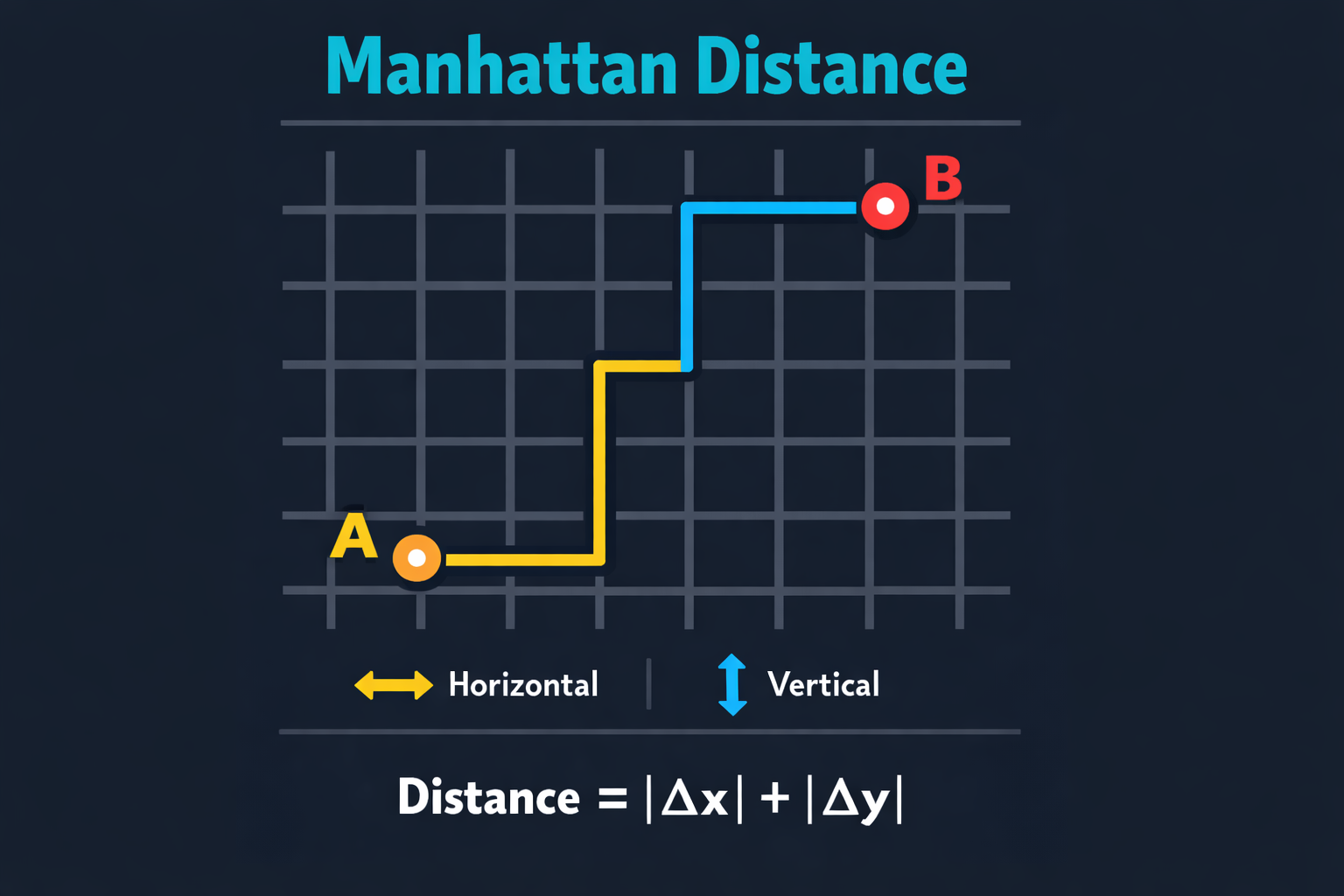
Manhattan Distance: sum of absolute differences along each axis
The Formula
d = |x₁ − x₂| + |y₁ − y₂|
Also called L1 distance or taxicab distance. It measures how far apart two points are by summing the absolute differences of their coordinates.
📐 Why Distance Matters for AI
Distance metrics are how machines measure similarity. They're foundational to search, recommendations, and retrieval.
Manhattan (L1): Sums absolute differences. Great for high-dimensional, sparse data. Used in clustering and nearest-neighbor search.
Euclidean (L2): Straight-line "as the crow flies" distance. The classic formula: √((x₁−x₂)² + (y₁−y₂)²). Sensitive to outliers.
Cosine Similarity: Measures the angle between two vectors, not the magnitude. This is what most embedding-based AI search uses today.
🔗 The Connection to AI
When an LLM-powered app searches for relevant documents, it converts text to vectors (embeddings) and uses distance metrics to find the closest matches. This is the heart of RAG — Retrieval Augmented Generation.
🧠 Knowledge Check 1
A delivery robot is at grid position (2, 3) and needs to reach (7, 6). What is the Manhattan distance?
💾 Topic 2: Data, Data, Data…
Before AI can help, it needs to reach your data. But enterprise data is scattered everywhere.
The modern data landscape: scattered, siloed, and diverse
Let's explore where your data actually lives — and why that matters for AI.
💾 Where Does Your Data Live?
ERP, CRM, HR systems — the "official" source of truth. Structured, governed, but often locked behind APIs. Examples: SAP, Salesforce, Workday.
Relational (SQL Server, PostgreSQL) and NoSQL (MongoDB, DynamoDB). Structured data with schemas — the easiest for AI to consume when properly connected.
Network drives, SharePoint, local folders. Word docs, spreadsheets, PDFs — a treasure trove of unstructured data that AI often can't see.
Massive volumes of institutional knowledge trapped in inboxes. Rich context, but privacy and compliance constraints make it tricky for AI.
Scalable object storage. S3 buckets can hold anything — images, logs, backups, data lake files. But storage ≠ understanding; data needs indexing.
🧠 Knowledge Check 2
Your team has years of client proposal documents saved on a shared network drive. Why might an LLM struggle to use this data effectively?
🔗 From RAG to GraphRAG
So how do we connect LLMs to data they've never seen? Enter Retrieval Augmented Generation (RAG).
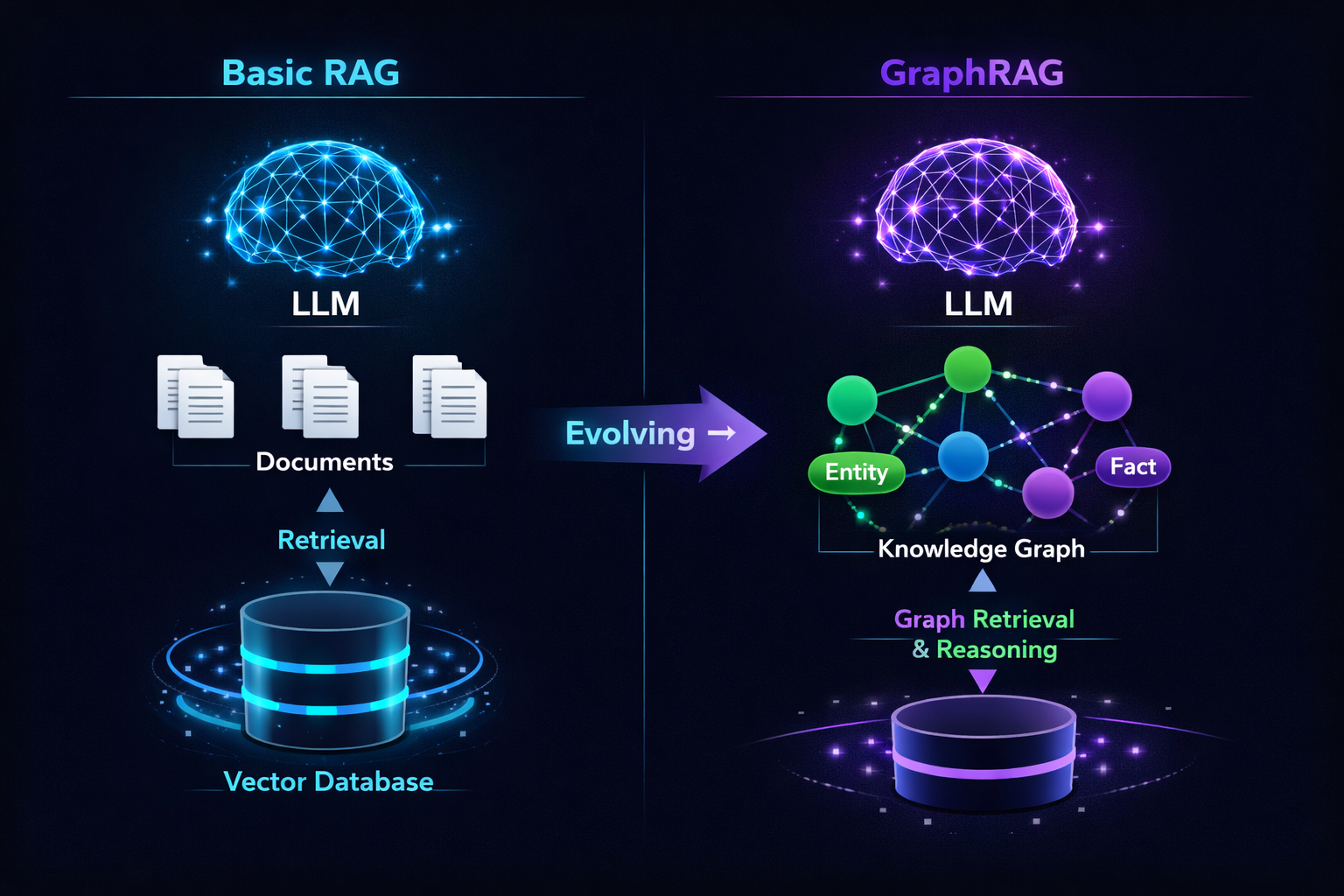
The evolution: from simple retrieval to knowledge-graph-powered generation
RAG retrieves relevant chunks of text from a vector database and feeds them to the LLM as context. It's the bridge between your data and the model.
🔗 GraphRAG: The Next Level
Step 1: Basic RAG
Documents → chunked → embedded as vectors → stored in a vector DB. User query is also embedded, and the nearest chunks are retrieved.
🧠 Knowledge Check 3
What is the key advantage of GraphRAG over basic RAG?
🧩 Topic 3: LLMs and Unseen Data
LLMs are powerful — but they have a fundamental limitation: they only know what they were trained on.
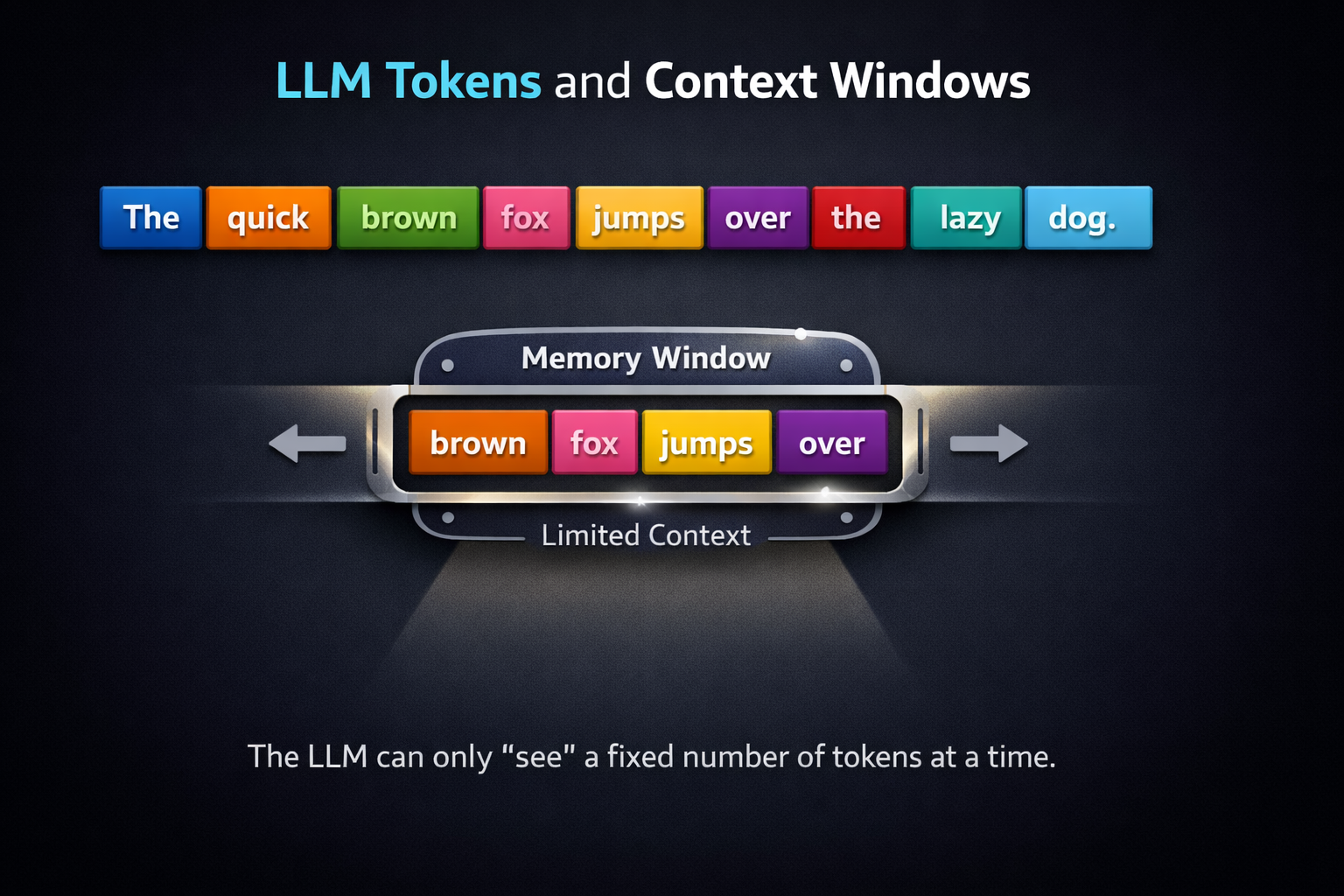
Text broken into tokens, viewed through a limited context window
The Knowledge Cutoff Problem
Every LLM has a training cutoff date. Ask about events after that date and the model has no data — it may hallucinate a plausible-sounding but incorrect answer.
🧩 Tokens: The Atoms of AI Language
Tokens are the smallest units an LLM processes. They're not exactly words — they can be word fragments, punctuation, or even single characters.
Rule of thumb: 1 token ≈ ¾ of a word in English.
The sentence "ChatGPT is amazing!" tokenizes roughly as:
That's ~5 tokens. Longer or unusual words get split into more pieces.
Tokens determine cost (you pay per token), speed (more tokens = slower), and what fits in the context window.
🪟 The Context Window
Think of the context window as the LLM's short-term memory. It's the total number of tokens the model can "see" at once.
GPT-3.5
~4K–16K tokens
GPT-4o
~128K tokens
Claude 3.5
~200K tokens
Gemini 1.5
~1M+ tokens
⚠️ Key Insight
Even with huge context windows, the LLM still only knows what's in that window right now plus its training data. Your private company data? Not included unless you put it there (via RAG, fine-tuning, or prompt injection).
🧠 Knowledge Check 4
An LLM with a 128K token context window is asked about your company's Q3 earnings report from last month. What is the most likely outcome?
🎯 Tying It All Together
Here's the full picture of how these three topics connect:
1️⃣ Distance = Similarity
Manhattan and other distance metrics are how AI finds relevant information. Text becomes vectors; closeness means relevance.
📝 Final Assessment
Time to test your understanding! Answer all 5 questions, then submit for your score.
📌 Rules
- 5 questions covering all three topics
- Each question is scored as correct or incorrect
- You'll see your total score after submitting
- Score 80% or higher to earn your certificate